

This article is an excerpt from the Shortform book guide to "The Signal and the Noise" by Nate Silver. Shortform has the world's best summaries and analyses of books you should be reading.
Like this article? Sign up for a free trial here.
Why do most predictions fail? How can we make better predictions that save people from catastrophic events?
In The Signal and the Noise, Nate Silver argues that our predictions falter because of mental mistakes such as incorrect assumptions, overconfidence, and warped incentives. However, he also suggests that we can mitigate these thinking errors with the help of a method called Bayesian inference.
Read below for a brief overview of The Signal and the Noise.
The Signal and the Noise by Nate Silver
The early 21st century has already seen numerous catastrophic failures of prediction: From terrorist attacks to financial crises to natural disasters to political upheaval, we routinely seem unable to predict the events that change the world. In The Signal and the Noise, Nate Silver sets out to explain why our predictions typically fail and how we can do better.
Silver is the creator of FiveThirtyEight, a political analysis website known for its track record of accurate forecasts of US elections. He’s also worked as a professional poker player and a baseball analyst—during which time he developed a well-respected system (PECOTA) for predicting players’ future performances.
In The Signal and the Noise, Silver explores a wide range of fields that depend on predictions, from politics, poker and baseball to economics, meteorology, and military intelligence. Though the book focuses mostly on these sorts of high-stakes examples, Silver suggests that its lessons are valuable for all readers—after all, decisions as mundane as what to wear on a given day are, in essence, predictions (for example, about the weather).
The book was originally published in 2012, though our guide is based on the updated 2020 version which includes a new preface discussing the 2016 US Presidential election and the early stages of the Covid-19 pandemic.
Part 1: Why Prediction Is Hard
Before we discuss our prediction mistakes and Silver’s advice for how to avoid them, it’s worth acknowledging that even under the best circumstances, prediction is an inherently challenging endeavor. In this section, we’ll explore Silver’s analysis of how insufficient information, system complexity, and the tendency of small errors to compound all limit the accuracy of our predictions.
We Often Lack Sufficient Information
To make good predictions, Silver says, you need information about the phenomenon you’re trying to predict as well as a good understanding of how that phenomenon works. For example, today’s meteorologists have abundant information about atmospheric conditions as well as a good understanding of the physical laws by which those conditions develop. Accordingly, Silver says, they can make reasonably accurate predictions about the weather.
The problem is that in many situations, we don’t have much useful data to go on. Silver illustrates this point by comparing meteorology to seismology, explaining that seismologists have no way to predict the timing, location, or strength of specific earthquakes. That’s because earthquakes happen rarely and on a geological timescale, which makes it hard to discern any patterns that might be at play. And whereas meteorologists can directly observe atmospheric conditions, there’s no way to measure factors such as the pressures currently at work on a given fault line nor to foresee future tectonic activity.
Many Systems Are Too Complex to Fully Understand
Also, Silver argues that even when we have rich data and a good understanding of the underlying principles, many systems still defy accurate prediction because of their inherent complexity. Silver discusses economic forecasts—which he says are notoriously unreliable—to lay out several ways complex systems hinder forecasting:
- They blur cause and effect, making it hard to determine root causes. For example, unemployment leads to a lack of consumer demand, which causes companies to scale down production and cut their workforces—which raises unemployment.
- They contain feedback loops that complicate their behaviors. For instance, employers, consumers, and politicians all make decisions based on economic forecasts, which means that the forecasts themselves can change the outcomes they’re meant to predict.
- Their rules and current status are unclear. Silver points out that economists don’t agree on what indicators might predict recessions; moreover, they often don’t realize when the economy is already in a recession (only recognizing that after the fact).
Small Errors Compound
Finally, Silver explains that even when you have good data and you’re not dealing with an inherently unpredictable system like the economy, your predictions are still limited by the fact that even minuscule mistakes in the predictive process compound into large errors over time. Silver argues that this principle of compounding error is at work even in fields with relatively accurate predictions, such as meteorology. Because each day’s weather depends on the previous day’s conditions, even the smallest inaccuracy in the initial data you plug into a simulation will add up to big discrepancies over time. Silver says that’s why weather forecasts are generally accurate a few days out but become increasingly unreliable the further into the future they try to predict.
Part 2: Why Our Predictions Are Worse Than They Could Be
So far, we’ve discussed challenges that are inherent to prediction—but according to Silver, these challenges don’t tell the whole story. Instead, he argues, we exacerbate these challenges through a series of mental errors that make our predictions even less accurate. In this section, we’ll examine these mental errors, which include making faulty assumptions, being overconfident, trusting data and technology too readily, seeing what we want to see, and following the wrong incentives.
We Make Faulty Assumptions
As we’ve seen, our predictions tend to go awry when we don’t have enough information or a clear enough understanding of how to interpret our information. This problem gets even worse, Silver says, when we assume that we know more than we actually do. He argues that we seldom recognize when we’re dealing with the unknown because our brains tend to make faulty assumptions based on analogies to what we do know.
To illustrate the danger of assumptions, Silver says that the 2008 financial crisis resulted in part from two flawed assumptions made by ratings agencies who gave their highest ratings to financial products called CDOs that depended on mortgages not defaulting.
- The first assumption was that these complicated new products were analogous to previous ones the agencies had rated. In fact, Silver suggests, the new products bore little resemblance to previous ones in terms of risk.
- The second assumption was that CDOs carried low risk because there was little chance of widespread mortgage defaults—even though these products were backed by poor-quality mortgages issued during a housing bubble.
Silver argues that these assumptions exacerbated a bad situation because they created the illusion that these products were safe investments when in fact, no one really understood their actual risk.
We’re Overconfident
According to Silver, the same faulty assumptions that make our predictions less accurate also make us too confident in how good these predictions are. One dangerous consequence of this overconfidence is that by overestimating our certainty, we underestimate our risk. Silver argues that we can easily make grievous mistakes when we think we know the odds but actually don’t. You probably wouldn’t bet anything on a hand of cards if you didn’t know the rules of the game—you’d realize that your complete lack of certainty would make any bet too risky. But if you misunderstood the rules of the game (say you mistakenly believed that three of a kind is the strongest hand in poker), you might make an extremely risky bet while thinking it’s safe.
Silver further argues that it’s easy to become overconfident if you assume a prediction is accurate just because it’s precise. With information more readily available than ever before and with computers to help us run detailed calculations and simulations, we can produce extremely detailed estimates that don’t necessarily bear any relation to reality, but whose numerical sophistication might fool forecasters and their audiences into thinking they’re valid. Silver argues that this happened in the 2008 financial crisis, when financial agencies presented calculations whose multiple decimal places obscured the fundamental unsoundness of their predictive methodologies.
We Trust Too Much in Data and Technology
As noted earlier, one of the challenges of making good predictions is a lack of information. By extension, the more information we have, the better our predictions should be, at least in theory. By that reasoning, today’s technology should be a boon to predictors—we have more data than ever before, and thanks to computers, we can process that data in ways that would have been impractical or impossible in the past. However, Silver argues that data and computers both present their own unique problems that can hinder predictions as much as they help them.
For one thing, Silver says, having more data doesn’t inherently improve our predictions. He argues that as the total amount of available data has increased, the amount of signal (the useful data) hasn’t—in other words, the proliferation of data means that there’s more noise (irrelevant or misleading data) to wade through to find the signal. At worst, this proportional increase in noise can lead to convincingly precise yet faulty predictions when forecasters inadvertently build theories that fit the noise rather than the signal.
Likewise, Silver warns that computers can lead us to baseless conclusions when we overestimate their capabilities or forget their limitations. Silver gives the example of the 1997 chess series between grandmaster Garry Kasparov and IBM’s supercomputer Deep Blue. Late in one of the matches, Deep Blue made a move that seemed to have little purpose, and afterward, Kasparov became convinced that the computer must have had far more processing and creative power than he’d thought—after all, he assumed, it must have had a good reason for the move. But in fact, Silver says, IBM eventually revealed that the move resulted from a bug: Deep Blue got stuck, so it picked a move at random.
According to Silver, Kasparov’s overestimation of Deep Blue was costly: He lost his composure and, as a result, the series. To avoid making similar errors, Silver says you should always keep in mind the respective strengths and weaknesses of humans and machines: Computers are good at brute-force calculations, which they perform consistently and accurately, and they excel at solving finite, well-defined, short- to mid-range problems (like a chess game). On the other hand, Silver says, computers aren’t flexible or creative, and they struggle with large, open-ended problems. Conversely, humans can do several things computers can’t: We can think abstractly, form high-level strategies, and see the bigger picture.
Our Predictions Reflect Our Biases
Another challenge of prediction is that many forecasters have a tendency to see what they want or expect to see in a given set of data—and these types of forecasters are often the most influential ones. Silver draws on research by Phillip E. Tetlock (author of Superforecasting) that identifies two opposing types of thinkers: hedgehogs and foxes.
- Hedgehogs see the world through an ideological filter (such as a strong political view), and as they gather information, they interpret it through this filter. They tend to make quick judgments, stick to their first take, and resist changing their minds.
- Foxes start not with a broad worldview, but with specific facts. They deliberately gather information from opposing disciplines and sources. They’re slow to commit to a position and quick to change their minds when the evidence undercuts their opinion.
Silver argues that although foxes make more accurate predictions than hedgehogs, hedgehog predictions get more attention because the hedgehog thinking style is much more media-friendly: Hedgehogs give good sound bites, they’re sure of themselves (which translates as confidence and charisma), and they draw support from partisan audiences who agree with their worldview.
Our Incentives Are Wrong
Furthermore, Silver points to the media’s preference for hedgehog-style predictions as an example of how our predictions can be warped by bad incentives. In this case, for forecasters interested in garnering attention and fame (which means more airtime and more money), bad practices pay off. That’s because all the things that make for good predictions—cautious precision, attentiveness to uncertainty, and a willingness to change your mind—are a lot less compelling on TV than qualities that lead to worse predictions—broad, bold claims, certainty, and stubbornness.
Similarly, Silver explains that predictions can be compromised when forecasters are concerned about their reputations. For example, he says, economic forecasters from lesser-known firms are more likely to make bold, contrarian predictions in hopes of impressing others by getting a tough call right. Conversely, forecasters at more esteemed firms are more likely to make conservative predictions that stick closely to the consensus view because they don’t want to be embarrassed by getting a call wrong.
Part 3: Better Predictions Through Bayesian Logic
Although prediction is inherently difficult—and made more so by the various thinking errors we’ve outlined—Silver argues that it’s possible to make consistently more accurate predictions by following the principles of a statistical formula known as Bayes’ Theorem. Though Silver briefly discusses the mathematics of the formula, he’s most interested in how the theorem encourages us to think while making predictions. According to Silver, Bayes’ Theorem suggests that we make better predictions when we consider the prior likelihood of an event and update our predictions in response to the latest evidence.
The Principles of Bayesian Statistics (bayesian principles)
Bayes’s Theorem—named for Thomas Bayes, the English minister and mathematician who first articulated it—posits that you can calculate the probability of event A with respect to a specific piece of evidence B. To do so, Silver explains, you need to know (or estimate) three things:
- The prior probability of event A, regardless of whether you discover evidence B—mathematically written as P(A)
- The probability of observing evidence B if event A occurs—written as P(B|A)
- The probability of observing evidence B if event A doesn’t occur—written as P(B|not A)
Bayes’ Theorem uses these values to calculate the probability of A given B—P(A|B)—as follows:
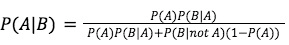
Bayesian Lesson #1: Consider All Possibilities
Now that we’ve explored the mathematics of Bayes’ Theorem, let’s look at the broader implications of its underlying logic. First, building on the principle of considering prior probabilities, Silver argues that it’s important to be open to a wide range of possibilities, especially when you’re dealing with noisy data. Otherwise, you might develop blind spots that hinder your ability to predict accurately.
To illustrate this point, Silver argues that the US military’s failure to predict the Japanese attack on Pearl Harbor in 1941 shows that it’s dangerous to commit too strongly to a specific theory when there’s scant evidence for any particular theory. He explains that in the weeks before the attack, the US military noticed a sudden dropoff in intercepted radio traffic from the Japanese fleet. According to Silver, most analysts concluded that the sudden radio silence was because the fleet was out of range of US military installations—they didn’t consider the possibility of an impending attack because they believed the main threat to the US Navy was from domestic sabotage by Japanese Americans.
Silver explains that one reason we sometimes fail to see all the options is that it’s common to mistake a lack of precedence for a lack of possibility. In other words, when an event is extremely uncommon or unlikely, we might conclude that it will never happen, even when logic and evidence dictate that given enough time, it will. For example, Silver points out that before the attack on Pearl Harbor, the previous foreign attack on US territory came in the early 19th century—a fact that made it easy to forget that such an attack was even possible.
Bayesian Lesson #2: Follow the Evidence, Not Emotions or Trends
In addition to emphasizing the importance of considering all possibilities, Bayesian logic also highlights the need to stay focused on the evidence rather than getting sidetracked by other factors such as your emotional responses or the trends you observe.
For one thing, Silver argues that when you give in to strong emotions, the quality of your predictions suffers. He gives the example of poker players going on tilt—that is, losing their cool due to a run of bad luck or some other stressor (such as fatigue or another player’s behavior). Poker depends on being able to accurately predict what cards your opponent might have—but Silver argues that when players are on tilt, they begin taking ill-considered risks (such as betting big on a weak hand) based more on anger and frustration than on solid predictions.
Furthermore, Silver says, it’s important not to be swayed by trends because psychological factors such as herd mentality distort behaviors in unpredictable ways. For instance, the stock market sometimes experiences bubbles that artificially inflate prices because of a runaway feedback loop: Investors see prices going up and want to jump on a hot market, so they buy, which drives prices up even further and convinces more investors to do the same—even when there’s no rational reason for prices to be spiking in the first place.
Part 4: Two Challenges for Today’s Forecasters
Although Silver maintains that his suggestions can improve the quality of our predictions, he cautions that it’s more difficult than ever to translate better prediction theory into better predictions in practice. We’ve already discussed one reason for that: namely, that contemporary technology forces us to wade through more noise to find meaningful signal. But Silver also argues that since the late 2010s, unprecedented political and social fragmentation have made prediction even harder. In this section, we’ll discuss how this fragmentation has complicated forecasters’ jobs by decreasing the diversity of thought and eroding public trust in expert advice.
Challenge #1: Increasingly Insular Groups
One problem for contemporary forecasters, according to Silver, is that contemporary news and social media encourage people to sort themselves into like-minded subgroups, which harms predictions by encouraging herd mentality and quashing opposing views. According to Silver, the best predictions often come when we combine diverse, independent viewpoints in order to consider a problem from all angles. Conversely, when you only listen to people who think the way you do, you’re likely to simply reinforce what you already believe—which isn’t a recipe for good predictions.
Challenge #2: The Erosion of Trust
Moreover, Silver argues, the same factors that have led to more insular, polarized groups have also led many people to dismiss opinions that come from outside of the group’s narrow consensus. One effect of this trend is that people trust public institutions and expert opinions less than ever before, which creates a climate in which people tend to dismiss accurate—and urgent—predictions, sometimes without clear reasons. He gives the example of the 2020 outbreak of Covid-19, when a significant number of people dismissed expert predictions about the virus’s likely spread and impact and, as a result, ignored or pushed back against the recommended public health protocols.
———End of Preview———
Like what you just read? Read the rest of the world's best book summary and analysis of Nate Silver's "The Signal and the Noise" at Shortform.
Here's what you'll find in our full The Signal and the Noise summary:
- Why humans are bad at making predictions
- How to overcome the mental mistakes that lead to incorrect assumptions
- How to use the Bayesian inference method to improve forecasts


")


