Neural networks have come a long way since their rocky start in the 1950s. Early systems could learn basic patterns, but these machines hit a wall when faced with real-world complexity. Funding dried up, and the field lay dormant for years. Breakthroughs in parallel processing, powerful computer chips, and massive datasets eventually brought neural networks back from the dead.
Continue reading to learn the early history of neural networks.
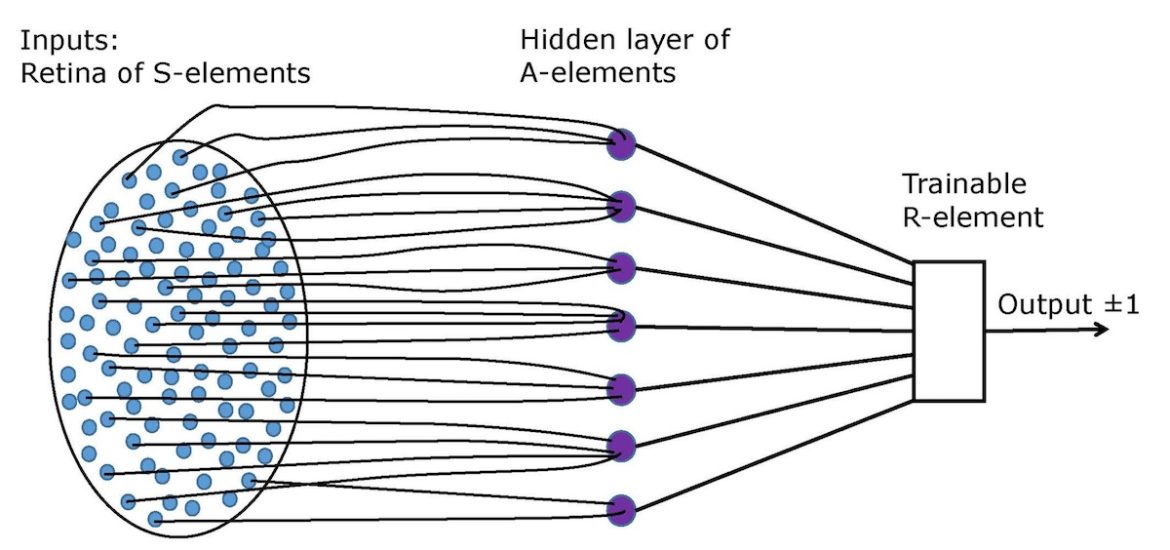
Image: An elementary Rosenblatt’s perceptron. Credit: Wikimedia Commons. License
The History of Neural Networks
In his book How to Create a Mind, Ray Kurzweil explains that the first serious attempts to build brain-like systems began with artificial neural networks in the 1950s. Early neural networks showed that simple processing units connected in networks could learn to recognize patterns. Frank Rosenblatt’s Mark I Perceptron, which Kurzweil encountered as a student, consisted of artificial neurons with adjustable connection weights that could be trained through feedback. While these networks could learn to distinguish between different categories of input, their limitations became apparent when researchers tried to scale them up to handle real-world complexity.
The most significant problem was invariant recognition—the ability to recognize the same pattern despite changes in size, position, rotation, or style. A neural network trained to recognize the letter “A” in one font and size would often fail to recognize the same letter in a different context. These early systems also required extensive training and still performed poorly on tasks that seemed effortless for humans. The field of neural networks stagnated for nearly two decades after Marvin Minsky and Seymour Papert demonstrated the mathematical limitations of the networks that existed at the time, a critique that effectively killed funding for neural network research until the 1980s.
| What Are Neural Networks? Neural networks are computer systems designed to loosely mimic how the human brain processes information. Stephen Witt explains in The Thinking Machine that neural networks learn by analyzing enormous datasets and adjusting millions of internal connections according to the patterns they discover. Neural networks were first proposed in 1944, gained steam in the 1950s and ’60s, then fell out of favor when it was proven that the simple neural networks of the time couldn’t solve certain types of problems. The idea had a renaissance in the 1980s, with more complex neural networks that could learn from their mistakes, but these were too slow and computationally demanding, so the idea stagnated again around 2000. The history of neural networks includes a crucial innovation: parallel processing. This mimics how the human brain computes, with billions of neurons working simultaneously. For decades, researchers had tried to recreate this in computers. By the 1980s, they showed that transistor circuits could mimic the way neural membranes work in the brain and developed “parallel distributed processing” frameworks. But it wasn’t until Nvidia built computer chips that provided the computational power neural networks needed—and researchers created massive datasets and the mathematical tools to extract meaningful patterns from them—that neural networks could finally solve problems such as invariant recognition that had stumped earlier systems. |
Explore Further
In How to Create a Mind, Kurzweil contends that understanding how the human brain works reveals why human-level AI is inevitable. Read Shortform’s guide to this book to understand how the history of neural networks fits into the bigger picture.